Do developers really understand HTTP?


Most of us are developing HTTP based applications (Android/iOS/Web Apps, IoT) on a daily basis, sometimes even without realising we are using HTTP behind the scenes (3rd party SDKs, even this article is served to you via HTTP). Most of us read about HTTP while preparing for a tech interview, as questions like
What happens when you type a URL in the browser and press enter?
How is HTTPS different from HTTP?
are expected.
Underlying implementation of HTTP has been abstracted from us and it is fair that most of us don’t get into low level implementation of it, but to understand the underlying protocol becomes crucial at times. All we know is we can make a HTTP request using a client (Postman, cURL, okhttp, Alamofire or your web browser).
But, how does the client make a HTTP request. To understand this let’s see what definition says
The Hypertext Transfer Protocol (HTTP) is an application protocol for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web.
Cool, it’s a protocol. So what are the rules? Let’s read a bit further
The request message consists of the following: - a request line* (e.g., GET /images/logo.png HTTP/1.1, which requests a resource called
/images/logo.pngfrom the server)
- *request header fields* (e.g., Accept-Language: en)
- an empty line
- *an optional message body
Nice, now we know what are the rules of a HTTP Request. Let’s put our science goggles on and experiment a bit.
Experiment Time 🥽
First, checkout data browser sends when it makes an request to *google.com*
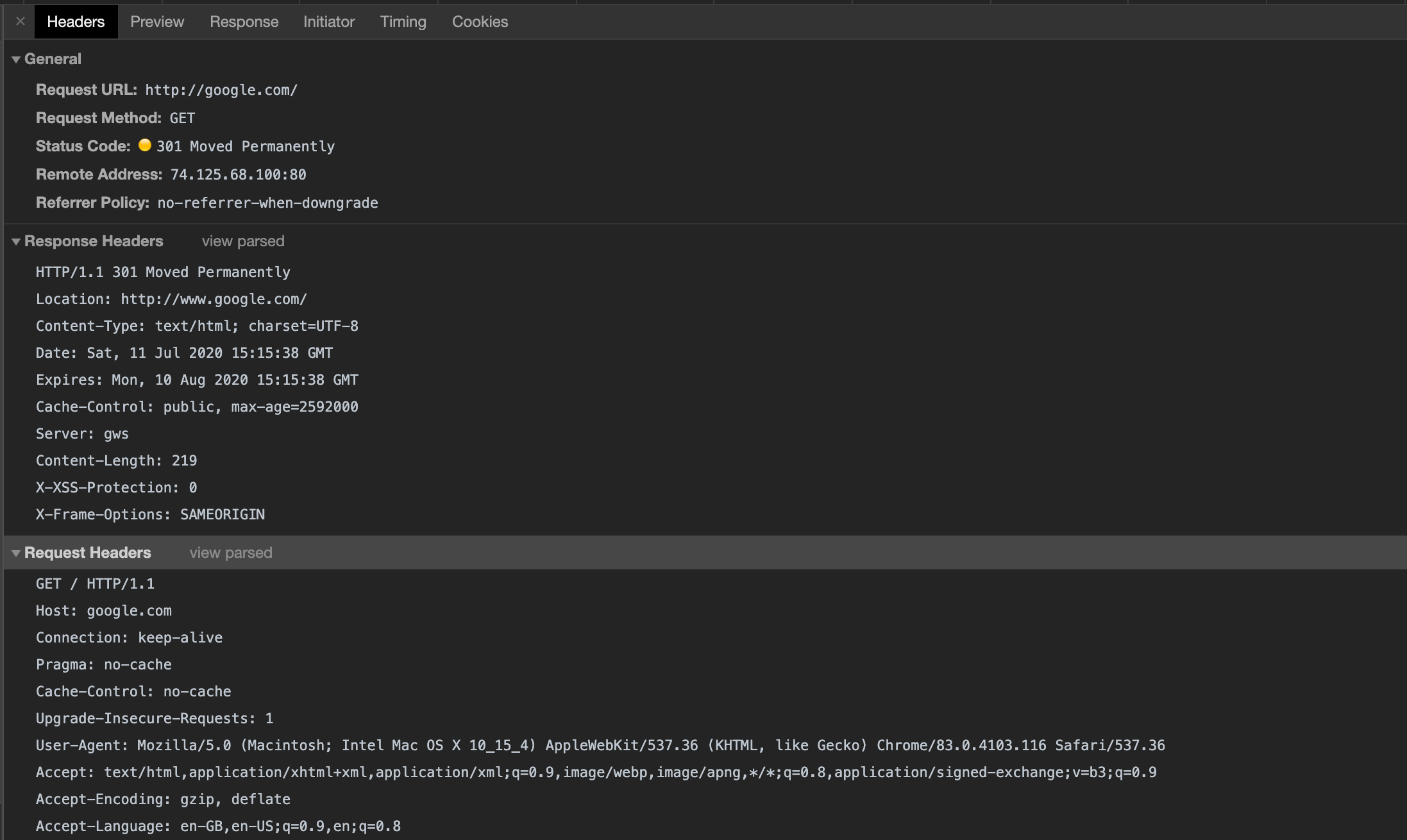 Snapshot of HTTP Request Chrome Developer Tools
Snapshot of HTTP Request Chrome Developer Tools
We have naively made request to google.com on http and not https to check out response from google server. We will understand about https in later articles. Stay tuned. :)
In response headers, we got 301 Moved Permanently to **http://www.google.com.**
So far so good, but that’s a browser doing everything under for us. How can we make the same request to google.com without a HTTP Client.
Roll your sleeves up and get ready to get your hands dirty on terminal. We will use an old cli-tool *telnet, *used to create TCP connections.
We will perform all the steps done by browser on our own:
- Connect to google.com on port 80, as http connects on port 80 by default. 3-way handshake is performed by telnet for us as it creates a TCP connection.
telnet google.com 80
 Response from google.com when connected to port 80
Response from google.com when connected to port 80
- Next is, to send an HTTP request over TCP connection to google.com. We will do this by sending the payload as per the protocol. As defined, we will have to put in an empty line to send payload (empty line at the end of below code block is intentional)
GET / HTTP/1.1
Host: google.com
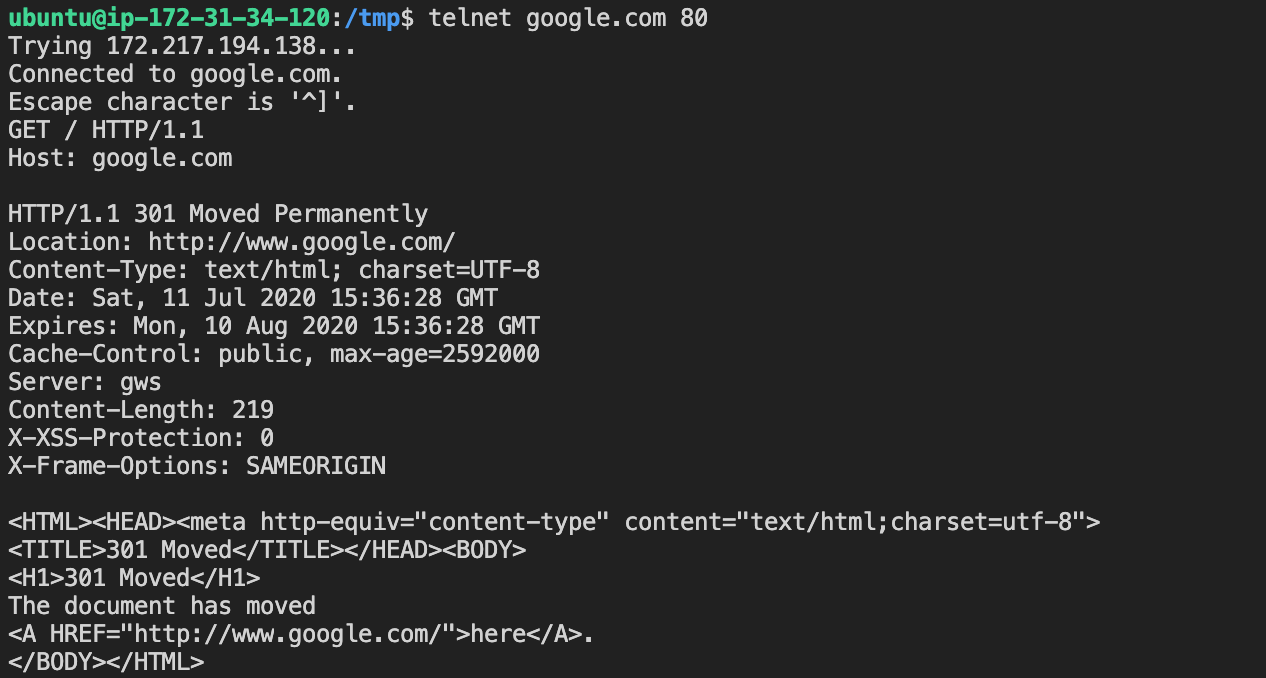 google.com responds with proper http response in telnet
google.com responds with proper http response in telnet
Oh look, they responded in a proper HTTP Response format without a HTTP client. If you compare this with the browser’s response it’s similar, except for some headers which we didn’t send in telnet request. HTTP client makes things easy for us by parsing response and providing us with an interface to access body / status code / headers.
This is a basic demonstration of how a HTTP request / response cycle works. There are few things which still needs clarifications
If we know the specifications of protocol, can we write our own HTTP Client? Short answer, YES.
Can we a make HTTPS request using telnet? Short answer, NO.
If you are interested in detailed articles about above questions, please leave your interest in comments. You can refer to MDN for detailed reading on HTTP.
Any critical feedback is appreciated as well as your thoughts on what we developers take for granted but we rarely try to understand how it works?